AI Dojo Platform Technical Design

Version 1.3
Last Updated: 31st March 2026
1. Introduction
1.1 Purpose
The purpose of this technical design document is to provide a comprehensive and detailed description of the AI Dojo Platform, a web-based SaaS solution that provides secure access to foundation AI models (leveraging multiple frontier model providers) and custom AI assistants. The platform is fully hosted and operated by AI Dojo within AI Dojo’s Microsoft Azure environment.
This document is intended to equip both AI Dojo’s internal engineering teams and customer technical stakeholders (such as IT, architecture, security, and risk teams) with the information required to understand the platform’s architecture, security model, data flows, integration patterns, and operational characteristics. It focuses on how the AI Dojo Platform is designed to be secure, robust, and efficient, supporting its safe adoption within customer ecosystems and its sustained, reliable operation as a SaaS service.
1.2 Scope
This document covers the technical architecture, multi-tenant design, security controls, integration points, and operational and maintenance processes for the AI Dojo Platform as a SaaS offering hosted within AI Dojo’s Microsoft Azure environment. It describes how the platform is provisioned, isolated per customer organisation, and operated by AI Dojo, including data protection, observability, and resilience measures.
The scope includes the ways in which the AI Dojo Platform can integrate with customer systems (such as identity providers and data sources), performance and capacity considerations, and the monitoring and support mechanisms that underpin ongoing reliability. Business-related topics such as pricing models, commercial terms, marketing strategies, or end-user training materials are explicitly out of scope; the focus is solely on technical implementation and operational aspects relevant to architecture, security, and IT due diligence.
1.3 Audience
This technical design document is intended for a diverse audience of internal and external stakeholders involved in the design, operation, evaluation, and adoption of the AI Dojo Platform as a SaaS service.
- AI Dojo Internal Team: Engineers, developers, security specialists, and technical architects within AI Dojo responsible for designing, developing, operating, and evolving the platform. This audience uses the document as a reference for the platform’s architecture, security model, operational processes, and integration patterns.
- Customer Stakeholders: Technical stakeholders within customer organisations, such as IT managers, enterprise and solution architects, security and risk teams, and compliance officers, who require an in-depth understanding of how the SaaS platform is architected, secured, and integrated into their ecosystem. Non-technical stakeholders, such as business managers and process owners, may also use this document to understand how the platform’s capabilities align with business objectives and governance requirements.
By addressing the needs of these groups, this document supports architectural and security review, IT due diligence, and informed decision-making regarding the onboarding and ongoing use of the AI Dojo Platform within customer environments.
1.4 Overview
The platform contains the following functional components:
- The ‘Home Base’ landing page - all Assistants are accessible from this page.
- The Chat History panel that persists on the left-hand side of the solution – provide ability to review historical chats, select the Home Base button to return to landing page, and access user-specific functions.
-
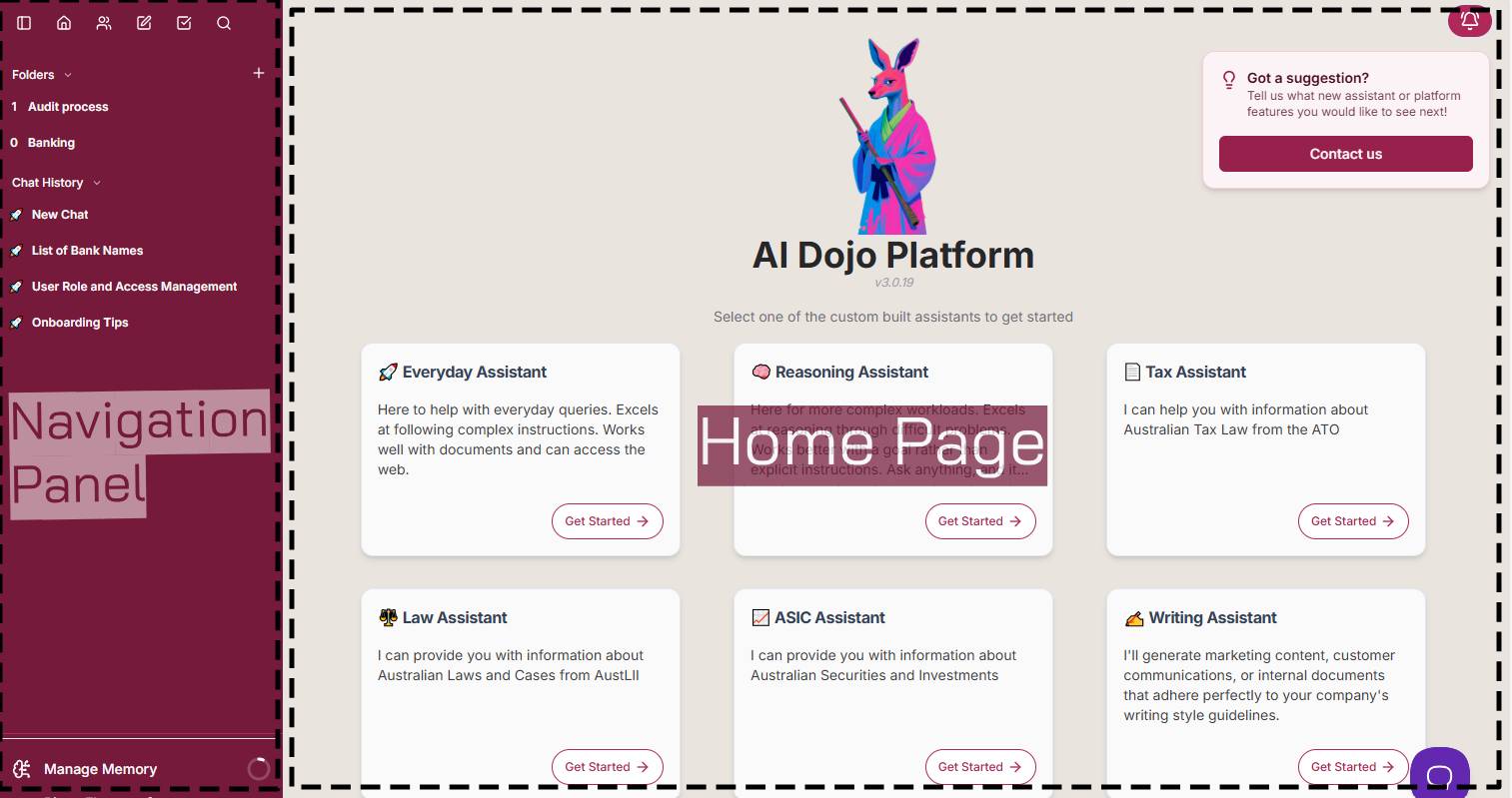
Figure 1: Home Page

- Assistant pages – dedicated pages where users can initiate chats with defined Assistants. These Assistants could be general AI models (for example, OpenAI GPT models and Anthropic Claude models), or custom Assistants that integrate to specific data sources like our Tax Assistant (integrates with ATO website).

2. System Architecture
2.1 Architecture Overview
The AI Dojo Platform is a cloud-native, multi-tenant SaaS solution hosted in AI Dojo’s Microsoft Azure environment. It provides specialised AI assistants tailored primarily for accounting and related professional services, accessible through a web-based interface. Users interact with the platform via a front-end application that communicates with a backend service responsible for assistant orchestration, prompt handling, and integration with external services such as model provider APIs (for example, OpenAI and Anthropic) and PostgreSQL.
The core platform consists of two main services: a front-end service and a backend assistants service, each deployed as Docker containers on shared Azure compute infrastructure. The multi-tenant architecture ensures that while the underlying infrastructure and application stack are shared, data and configuration are logically isolated per customer organisation. The platform primarily operates in a production mode, with separate non-production environments used by AI Dojo for development, testing, and staging. This design allows the platform to scale efficiently and integrate with external services such as model provider APIs (for example, OpenAI and Anthropic) and PostgreSQL.

2.2 Components Description
Users
Users interact with the AI Dojo Platform through a web front-end. Access is typically provided via the customer’s identity provider (e.g. Microsoft Entra ID) and enforced using role-based access controls.
Azure Resource Group
All production and non-production resources for the AI Dojo Platform are deployed into Azure resource groups managed by AI Dojo. These resource groups contain both platform services and the supporting networking, storage, and monitoring components.
Azure Linux Virtual Machines (Prod / Dev)
Azure Linux virtual machines host the platform services as Docker containers in both production and development environments:
- Front-end container
- Provides the web application used by end users.
- Handles authentication, session management, and UI rendering.
- Communicates securely with the backend assistants service via HTTPS.
- Assistants (backend) container
- Acts as the core application backend and API surface for the platform.
- Manages organisation configuration, request routing to AI assistants, and integration with external services such as Model Provider APIs (OpenAI, Anthropic), PostgreSQL, Redis, and storage.
- Implements business logic for accounting-focused assistants (e.g. General Ledger Assessment, Financial Statement and Tax Return Review).
- Redis
- Provides in-memory caching and transient state to improve performance and responsiveness (for example, caching configuration, session-related data, or intermediate AI responses).
Networking Resources (Prod / Dev)
Each environment includes supporting Azure networking components:
- Virtual Networks and Subnets for isolating platform services and controlling traffic flows.
- Network Interfaces and Network Security Groups (NSGs) to control and restrict inbound and outbound traffic at the VM/network level.
- Public IP Addresses used for controlled external access to the platform.
Databricks VNet Peering
The Azure Databricks workspace operates on a dedicated VNet that is peered to both the production and development platform VNets. This peering enables Databricks clusters and jobs to access platform storage accounts and other services over private network paths without traversing the public internet.
Azure Database for PostgreSQL Server
A managed Azure Database for PostgreSQL instance is used to persist:
- Organisation configuration and metadata.
- Chat history and audit-relevant interaction data.
- Other platform data structures.
Multi-organisational data is logically isolated within the database according to organisation identifiers and access controls enforced at the application layer.
Azure Storage Accounts
Azure Storage Accounts are used to store:
- User-uploaded files (e.g. documents analysed by assistants).
- Static content and other persistent application artefacts as required.
- Unity Catalog external location data for Azure Databricks.
All data is encrypted at rest using Azure-managed keys, with access controlled via identity and network rules. Databricks Access Connectors authenticate to storage accounts using managed identities with least-privilege role assignments.
Azure Databricks
A VNet-injected Azure Databricks workspace is deployed on a dedicated Virtual Network. The Databricks VNet is peered to both the production and development platform VNets, enabling secure connectivity to platform storage accounts and other services without traversing the public internet. Unity Catalog is configured as the centralised data governance layer.
Azure Container Registry
An Azure Container Registry is used to store built container images
for the front-end and assistants (backend) services.
Azure Front Door and CDN Profiles
Azure Front Door and associated CDN profiles are used to efficiently deliver organisation-specific branding assets to end users:
- Serve organisation-level branding artefacts (such as hero images, favicons, and other static assets) that are stored in Azure Storage Accounts.
- Optimise performance and latency for these assets via caching and global content distribution.
- Provide a secure, scalable entry point and routing layer in front of the platform for static branding resources exposed to the front-end UI.
Monitoring and Alerts
- Metrics and Alerts (e.g. high CPU, low memory usage on VMs or containers) to detect resource constraints and performance issues.
Environments (Prod and Dev)
The diagram distinguishes:
- Prod Platform and Prod Related Resources – the primary, customer-facing multi-organisation environment.
- Dev Platform and Dev Related Resources – used internally by AI Dojo for development, testing, and staging of changes before promotion to production.
2.3 Interactions and Data Flow
-
User Interaction with Front-End
Users access the AI Dojo Platform via the web front-end. After authenticating (typically via Microsoft Entra ID), they select an assistant and submit prompts, optionally uploading documents for analysis. The front-end sends these requests securely to the backend assistants service over HTTPS.
-
Request Handling by Assistants Backend
The assistants backend receives the request, validates organisation and user context, and determines which assistant configuration to apply (for example, accounting-focused assistants or client communications assistant). It prepares the prompt, applies any organisation-specific settings, and orchestrates calls to downstream services.
-
AI Processing via Model Provider APIs (OpenAI and Anthropic)
The backend invokes a selected model provider (OpenAI or Anthropic) to generate responses, passing the constructed prompt and any relevant contextual information. The selected provider returns an AI-generated response, which the backend may further post-process (for example, formatting) before returning it to the user.
-
Use of Redis for Caching and Transient State
Redis is used by the backend to cache chat data and to manage transient state that improves response times and scalability. This reduces load on PostgreSQL for repeated reads.
-
Database Access for Organisation Data and Chat History
The backend reads and writes organisation-specific data to Azure Database for PostgreSQL, including organisation profiles and chat history. Multi-organisation data is logically separated by organisation identifiers, with access enforced at the application layer.
-
Storage of User Files and Branding Assets
User-uploaded and assistant-generated files are stored in Azure Storage Accounts. Organisation-specific branding files (such as hero images and favicons) are also stored here and delivered to end users via Azure Front Door/CDN. All storage access is controlled and audited.
-
Response Delivery to Users
Once the AI response and any supporting data are assembled, the backend returns a structured response to the front-end. The front-end renders the message, file references, and any assistant-specific UI elements in the user’s browser.
-
Application Logging and Auditing
Application-level logs and audit events (such as request metadata, errors, and key operational events) are written to dedicated tables in Azure Database for PostgreSQL. These logs support troubleshooting, monitoring, and compliance reporting across all organisations.
2.4 Infrastructure Technology Stack
The following table summarises the core Microsoft Azure services and infrastructure components used to host and operate the AI Dojo Platform.
| Technology | Description |
|---|---|
| Azure Linux Virtual Machines | Host the front-end and assistants (backend) services, each running as Docker containers in both production and development environments. |
| Docker Containers (Front-end and Assistants) | The front-end container provides the web UI and communicates with the backend over HTTPS. The assistants container implements core platform logic, organisation handling, and integrations with model providers, PostgreSQL, Redis, and storage. |
| Azure Database for PostgreSQL | Primary relational data store for the platform. Persists organisation configuration, user data, chat history, and application/audit logs in dedicated tables. Multi-organisation data is logically isolated using organisation identifiers. |
| Redis | In-memory cache used by the backend for transient data, improving performance and reducing load on PostgreSQL. |
| Azure Storage Accounts | Store user-uploaded and assistant-generated files, organisation-specific branding artefacts, and Unity Catalog external location data. |
| Azure Front Door and CDN Profiles | Deliver organisation-specific branding assets from Azure Storage to end users, providing secure, low-latency access and caching for static content. |
| Microsoft Entra ID | Secures access to the platform through authentication and authorisation, supporting single sign-on and role-based access control for users. |
| Azure Key Vault | Centrally stores secrets and environment variables for platform containers. Secrets are retrieved at runtime via an automated script, stored in ephemeral VM storage, and injected into containers at startup. |
| Azure Databricks | VNet-injected workspace on a dedicated VNet peered to production and development platform VNets. Provides Unity Catalog for centralised data governance, with per-environment catalogs backed by external locations on platform ADLS Gen2 storage accounts. |
| Databricks Access Connectors | Per-environment managed identity connectors providing least-privilege access to platform storage accounts |
| Azure Container Registry | Stores built images for the frontend and assistants (backend) services. |
2.5 Application and External Services Stack
The following diagram provides a high-level view of the AI Dojo Platform application stack (front-end and backend technologies) and the key external services integrated with the platform. This diagram is intended to complement the infrastructure-focused architecture described in Sections 2.1–2.4.

3. Deployment Model

3.1 Deployment Topology
The AI Dojo Platform is deployed and operated by AI Dojo within AI Dojo–managed Azure subscriptions. All deployments are automated using Infrastructure as Code and Azure DevOps pipelines.
Azure DevOps (AI Dojo)
- AI Dojo uses GitHub for source control and CI/CD pipelines (via GitHub Actions), with Jira used for project and work item tracking. The platform source code is maintained in separate development and production branches within the same repository. CI/CD pipelines build container images, run automated tests, and publish images to the AI Dojo container registry.
Infrastructure as Code and App Registrations
- Terraform (and related Infrastructure as Code tooling) is used to provision and update Azure resources, including virtual machines, networking, storage, databases, monitoring, and required app registrations (for example, Microsoft Entra ID applications).
Container Registry (AI Dojo)
- Built images for the front-end and assistants (backend) services are pushed to an AI Dojo–managed container registry. Versioning and promotion between development and production are controlled via GitHub pipelines and release processes.
Platform Virtual Machines
- Azure Linux VMs in each environment (development and production) are configured to regularly check the AI Dojo container registry for updated images. When new versions are available, the VMs pull the latest images and restart the relevant containers in a controlled manner, ensuring that the platform runs the current, validated release.
Branding Storage Container (AI Dojo)
- Organisation-specific branding assets (for example, hero images, favicons, and other static files) are stored in an AI Dojo–managed storage container. The front-end retrieves these assets via Azure Front Door/CDN, allowing AI Dojo to apply or update customer branding without redeploying application code.
3.2 Environment Configuration
-
Production Environment
The production environment is the primary, customer-facing multi-organisation deployment of the AI Dojo Platform. It runs production branches of the front-end and backend containers, connected to production-grade PostgreSQL, Redis, storage, and networking resources. Changes are promoted into production only after passing through AI Dojo’s release and validation processes.
-
Development / Non-Production Environments
AI Dojo maintains separate non-production environments for building, testing, and validating changes prior to release. These environments mirror the production architecture as closely as practical but may use scaled-down resources. Non-production environments are not exposed to end users and are used solely by AI Dojo’s internal teams.
3.3 High Availability and Scalability
High Availability
- The core platform services (front-end and backend containers) run on Azure Linux VMs designed for resilient operation. The underlying Azure Database for PostgreSQL uses built-in Azure high-availability and backup capabilities to protect data and support recovery in the event of failures. Additional resilience measures (such as zone-redundant infrastructure or multiple VMs) can be introduced as the service scales.
Scalability
- The AI Dojo Platform can be scaled by increasing compute resources (for example, VM size or number of instances), scaling PostgreSQL and Redis capacity, and optimising caching and data access patterns.
4. Security
4.1 Security Requirements
The AI Dojo Platform is designed and operated as a multi-organisation SaaS service hosted within AI Dojo’s Microsoft Azure environment. The platform adheres to the following security requirements:
- Data Protection: Customer data (including prompts, chat history, uploaded files, and configuration) must be protected in transit and at rest using industry-standard encryption and secure key management practices.
- Organisation Isolation: Customer organisations must be logically isolated to prevent unauthorised access or data leakage between organisations. Organisational context must be enforced consistently across application logic, storage access, and database operations.
- Authentication and Authorisation: Access to the platform must be restricted to authorised users and systems using secure authentication (for example, Microsoft Entra ID) and role-based access controls to enforce least privilege.
- Secure Operations and Change Control: Platform infrastructure and application changes must be deployed through controlled, auditable processes (for example, CI/CD with approvals) with repeatable configuration management and segregation between production and non-production environments.
- Infrastructure and Application Hardening: Underlying compute, networking, and application components must be hardened in accordance with Azure and industry best practices, with regular patching and vulnerability management to minimise exposure.
- Network Security: All external and internal communications must use secure protocols (for example, HTTPS/TLS). Network controls must restrict inbound and outbound traffic to required paths only, and prevent unauthorised access to administrative interfaces and data services.
- Monitoring, Logging, and Auditability: Security-relevant events and application logs must be captured to support operational monitoring, incident investigation, and compliance reporting. Application-level logs and audit records are persisted in dedicated PostgreSQL tables with access controls and retention policies appropriate to the service.
- Availability and Resilience: The platform must be designed to maintain availability and recoverability appropriate for a production SaaS offering, including backups for persistent data stores and defined recovery procedures.
4.2 Identity and Access Management
Authentication
The AI Dojo Platform uses Microsoft Entra ID for user authentication, enabling secure single sign-on (SSO). The platform is registered as a multi-tenant Microsoft Entra ID application, allowing customer organisations to authorise access from their own Entra tenant via standard consent and enterprise application controls.
Terminology note: The term Entra tenant refers to a customer’s Microsoft Entra ID directory. The term organisation refers to a tenant entity within the AI Dojo Platform. Users authenticate via Entra ID and are then authorised within one or more organisations in the platform. By default, organisations are mapped to an email domain (and therefore commonly align to a single Entra tenant), however the platform supports a user belonging to multiple organisations where configured.
Platform Roles and Authorisation (RBAC)
Role-based access control is enforced within the application to ensure least-privilege access:
- AI Dojo Super Admins: Restricted to authorised AI Dojo employees for platform operations, support, and administration across organisations.
- Organisation Admins: Customer-designated administrators within a specific organisation (tenant) who can access the platform’s admin portal to manage users and organisation-level configuration within their own organisation.
- Organisation Users: Standard end users restricted to permitted assistants and organisation-scoped data.
Authorisation decisions are made using authenticated identity claims (including organisation context) and platform role assignments.
Organisation (Tenant) Isolation and Context Enforcement
All requests are associated with an organisation identifier derived from authenticated context and platform configuration. The platform enforces organisation context across application logic and data access to ensure users can only access assistants, configuration, files, chat history, and logs belonging to their organisation.
Customer Identity Controls (Entra ID)
Customer organisations can apply additional identity governance controls within their own Entra ID tenant (for example, MFA and Conditional Access policies). Customers may also restrict which users can sign in by controlling access to the enterprise application, however day-to-day user access management is primarily performed through the AI Dojo Platform’s organisation admin portal.
Administrative Access to Underlying Infrastructure
Access to AI Dojo’s Azure infrastructure resources (such as virtual machines, storage accounts, PostgreSQL, Redis, and networking) is restricted to AI Dojo’s authorised operational personnel. Customers do not receive direct access to underlying infrastructure resources as part of the SaaS offering.
Databricks Access and Governance
Access to Azure Databricks and Unity Catalog resources is governed through a combination of Databricks Access Connectors (managed identity-based) and Unity Catalog grants:
- Databricks Access Connectors (connector-prod, connector-test) authenticate to platform storage accounts using managed identities, with least-privilege Azure RBAC role assignments
- Unity Catalog grants control access to catalog objects (schemas, tables, external locations) on a per-environment basis. Access is granted as appropriate to each environment.
Future Identity Provider Support
While Microsoft Entra ID is the supported identity provider for the current release, the platform roadmap includes support for additional identity providers and federation methods as required by customers.
4.3 Data Security
Encryption
- Data in Transit: All data exchanged between users, the AI Dojo Platform, and supporting services is encrypted using TLS 1.2 or higher.
- Data at Rest: Data stored by the platform (including uploaded files in Azure Storage and relational data in Azure Database for PostgreSQL) is encrypted at rest using Azure-managed encryption mechanisms (AES-256).
Network-Level Protection (Firewall / IP Whitelisting)
- Azure Database for PostgreSQL and Azure Storage Accounts are protected using firewall rules and IP allowlists to restrict access to approved platform infrastructure only (for example, the production and development platform virtual machines).
Data Storage and Segregation
- Azure Database for PostgreSQL: Stores organisation configuration, user records, role assignments, chat history, and platform logs/audit events. Organisation data is logically segregated using organisation identifiers, with access enforced by application-layer authorisation controls.
- Azure Storage Accounts: Store user-uploaded files and organisation-specific branding assets. Access is restricted to platform services and controlled through identity and network policies.
- ADLS Gen2 and Unity Catalog Storage: The platform storage accounts have been migrated to ADLS Gen2 to support Azure Databricks Unity Catalog external locations. Dedicated containers store catalog-managed data. Access to these containers is mediated by Databricks Access Connectors using managed identities, and Unity Catalog grants enforce object-level access control within each environment's catalog.
Third-Party Processing (Model Provider APIs: OpenAI and Anthropic)
When generating assistant responses, the AI Dojo Platform may transmit customer content (such as prompts, uploaded-document extracts, and model outputs) to third-party model providers (OpenAI and/or Anthropic) for inference.
OpenAI (API inference)
AI Dojo configures OpenAI API usage such that customer content is not shared for OpenAI model training or improvement (i.e. opted out of data sharing for training/improvement where available in OpenAI settings). The platform also disables response storage for relevant requests (for example, store=false ).
Anthropic (API inference)
By default, Anthropic states it will not use inputs or outputs from its commercial products (including the Anthropic API) to train its models.
Anthropic states that for Anthropic API users, it automatically deletes inputs and outputs on its backend within 30 days of receipt or generation, except in specific cases (e.g. where longer retention is under customer control, by agreement, for usage policy enforcement, or legal compliance).
Access Control
Access to sensitive data is restricted using the platform’s RBAC model (AI Dojo super admins, organisation admins, and organisation users) and least-privilege access for services. Data access is always evaluated in the context of the authenticated user and organisation (tenant).
Secrets and Credentials
Service credentials and secrets are stored in Azure Key Vault. At container startup, an automated script retrieves secrets and stores them in ephemeral storage on the VM before attaching them to the Docker runtime. This ensures secrets are not persisted to disk and are scoped to the container lifecycle. Access to Key Vault is restricted to authorised services and AI Dojo operational personnel, and managed identities are used where supported to reduce reliance on long-lived credentials.
Logging and Auditability
Application logs and audit-relevant events are written to dedicated tables within Azure Database for PostgreSQL. Log access is restricted to authorised roles and used to support troubleshooting, security monitoring, and incident investigation.
Azure Security Features Utilised
The following table summarises the Microsoft Azure security features utilised by the AI Dojo Platform to protect customer data and maintain secure operations.
| Azure Security Feature | How AI Dojo Uses It |
|---|---|
| Azure-managed encryption (AES-256) | All data at rest (PostgreSQL, Storage Accounts, VM disks) is encrypted using Azure-managed keys. |
| TLS 1.2+ enforcement | All external and internal communications (user to platform, platform to Azure services, platform to model providers) use TLS 1.2 or higher. |
| Network Security Groups (NSGs) | Restrict inbound and outbound traffic to platform VMs; only required ports and paths are exposed. |
| Azure Firewall / IP allowlisting | Azure Database for PostgreSQL and Azure Storage Accounts are restricted to platform infrastructure IP addresses only. |
| Azure Key Vault | Centrally stores secrets and credentials; accessed via managed identities where supported to minimise long-lived credentials. |
| Azure Update Manager | Automated security patching for Ubuntu VMs with a weekly maintenance window (Sunday early morning AEST). |
| Azure Monitor / Metrics and Alerts | Infrastructure health monitoring with alerts for resource thresholds (for example, high CPU, low memory). |
| Azure Database for PostgreSQL managed backups | Automated daily snapshot backups and point-in-time restore within a 7-day retention window (supporting RPO ≤ 5 minutes). |
| Microsoft Entra ID (multi-tenant application) | Enterprise single sign-on (SSO) with support for customer-enforced MFA and Conditional Access policies. |
| Azure Front Door / CDN | Secure, low-latency delivery of organisation-specific branding assets with caching and global distribution. |
By leveraging these Azure-native security features, AI Dojo ensures that foundational infrastructure security is managed by Microsoft's certified and audited platform, while AI Dojo maintains responsibility for application-layer controls and operational security.
4.4 Compliance and Regulatory Considerations
The Platform is designed to support Australian regulatory and customer governance requirements:
- Australian Privacy Principles (APPs): The platform is designed to support compliance with the Australian Privacy Act 1988 and the Australian Privacy Principles through appropriate controls for data handling, access restriction, and auditability.
- Data Residency (AI Dojo Platform Data Stores): The AI Dojo Platform and all AI Dojo–managed data stores are deployed in Microsoft Azure Australia East, ensuring data residency within Australia. This includes:
- Azure Database for PostgreSQL (organisation configuration, chat history, audit logs)
- Azure Storage Accounts (user-uploaded files, branding assets)
- Redis (transient cache)
- Azure Linux Virtual Machines (application containers)
- Azure Key Vault (secrets and credentials)
- Azure Databricks workspace and Unity Catalog
- Azure Container Registry
- Microsoft Azure provides data residency commitments for these services within the Australia East region. For further detail, refer to Microsoft Azure data residency documentation.
- Customer Governance Alignment: Customers can apply additional controls through their own Microsoft Entra ID tenant (for example, MFA and Conditional Access policies) and through platform role assignments (organisation admins and users) to align platform use with internal security and compliance requirements.
- Model Provider Data Handling (OpenAI and Anthropic): The platform uses third-party model provider APIs for inference. When generating AI assistant responses, the AI Dojo Platform transmits customer content (such as prompts and document extracts) to these providers, which may process data outside Australia.
- As documented by OpenAI, data sent to the OpenAI API is not used to train or improve OpenAI models unless explicitly opted in. AI Dojo has configured OpenAI usage to opt out of data sharing for training/improvement and to disable response persistence (for example,
store=false). OpenAI may retain API content in abuse monitoring logs for up to 30 days by default (unless legally required to retain longer). - As documented by Anthropic for commercial offerings (including the Anthropic API), inputs/outputs are not used for model training by default, and Anthropic API inputs/outputs are deleted within 30 days except in defined circumstances (for example, usage policy enforcement or legal requirements).
- Customers with strict Australian data residency requirements should consider these third-party processing flows when assessing the platform's suitability for their use case. AI Dojo can discuss alternative configurations or model provider options where required.
- Configurable Compliance: Where required, the platform can be configured to support additional customer compliance requirements, subject to feasibility and agreed implementation scope.
Inherited Azure Compliance Certifications
The AI Dojo Platform is hosted on Microsoft Azure Australia East, which holds a comprehensive set of compliance certifications relevant to Australian enterprises and professional services firms. By hosting on Azure, AI Dojo inherits the foundational infrastructure-level controls validated by these certifications.
Key Azure certifications inherited by the AI Dojo Platform include:
| Certification / Framework | Relevance |
|---|---|
| ISO/IEC 27001 | International standard for information security management systems (ISMS). |
| ISO/IEC 27017 | Cloud-specific security controls guidance. |
| ISO/IEC 27018 | Protection of personal data in public cloud environments. |
| SOC 1, SOC 2, SOC 3 | Independent assurance over security, availability, processing integrity, confidentiality, and privacy controls. |
| IRAP (PROTECTED) | Australian Government Information Security Registered Assessors Program — assessed to PROTECTED level. |
| PCI DSS | Payment Card Industry Data Security Standard (applicable where payment data is processed). |
| Australian Privacy Principles (APPs) | Azure's alignment with the Privacy Act 1988 and APPs for Australian customers. |
For the full list of Azure compliance offerings, refer to the Microsoft Azure Compliance Offerings documentation.
How AI Dojo extends these controls:
AI Dojo leverages Azure's certified infrastructure for foundational controls including physical security, host and network infrastructure, platform-level encryption (AES-256 at rest, TLS 1.2+ in transit), and managed service availability. AI Dojo's own security programme extends these controls to the application layer, including:
- Multi-organisation (tenant) isolation and RBAC enforcement
- Application-level logging and audit trails
- Secrets management and credential handling
- Secure SDLC, change control, and patch management
- Incident response and disaster recovery procedures
AI Dojo is pursuing SOC 2 Type II and ISO/IEC 27001 certification for the AI Dojo Platform to provide independent assurance over these application-layer controls.
4.5 Threat Model and Mitigation
| Potential Threat | Corresponding Mitigation Strategy |
|---|---|
| Unauthorised Access: Risk of unauthorised users gaining access to the platform or elevated privileges within an organisation (tenant) or across tenants. | Strong Authentication and Identity Controls: Use Microsoft Entra ID for SSO, with customers able to enforce MFA and Conditional Access. Apply least privilege via platform RBAC, including strict separation of AI Dojo super admin capabilities and organisation admin/user roles. |
| Organisation Isolation Failure: Risk of misconfiguration or application defects leading to cross-organisation data exposure. | Organisation Context Enforcement: Enforce organisation (tenant) scoping throughout application logic and data access. Validate organisation context on every request and for every database/storage operation to prevent cross-organisation access. |
| Data Breach / Data Exfiltration: Exposure of customer data due to weak access controls, credential compromise, or misconfigured storage/database/network rules. | Network Controls and Firewalls: Restrict access to PostgreSQL and Storage Accounts using firewall rules and IP allowlists limited to the platform infrastructure. Limit VM inbound traffic to required ports and paths using NSGs and controlled entry points. |
| Credential and Secret Compromise: Exposure of sensitive credentials (for example, Model Provider API keys, database credentials, signing secrets) through insecure storage, logging, or operational access. | Secure Secrets Management: Secrets are stored in Azure Key Vault and retrieved at runtime via an automated script, then held in ephemeral VM storage and injected into containers at startup. This avoids persisting secrets on disk. Access to Key Vault is restricted, credentials are rotated where appropriate, and secrets are prevented from being written to logs. |
| Application Vulnerabilities: Exploitation of vulnerabilities in the web application, backend APIs, container images, or underlying VM OS. | Secure SDLC and Change Control: Use CI/CD pipelines with reviews and approvals, automated testing, and controlled promotion from non-production to production. Maintain auditable Infrastructure as Code for repeatable, consistent deployments. |
| Supply Chain Risk: Malicious or vulnerable third-party dependencies or container base images impacting platform integrity. | Hardening and Patch Management: Regularly patch VM operating systems and container base images. Apply vulnerability management processes for application dependencies and container images. |
| Denial of Service (DoS): Attacks that disrupt availability through request flooding, resource exhaustion, or abuse of AI endpoints. | Rate Limiting and Abuse Controls: Implement request throttling, resource limits, and guardrails to reduce the impact of DoS and excessive usage. Use caching (Redis) and capacity controls to protect shared resources. |
| Data Loss / Corruption (Accidental or Malicious): Risk of customer or platform data being deleted, corrupted, or rendered unrecoverable due to human error, software defects, malicious activity, or underlying infrastructure failure. | Backups and Recovery: Use managed database backup capabilities and Infrastructure as Code to support restoration and recovery following incidents or failures. |
| Prompt Injection / Data Leakage via AI: Attempts to manipulate assistant behaviour to disclose sensitive information, bypass controls, or retrieve data outside the user’s organisation context. | AI Safety and Data Leakage Controls: Apply defensive prompting and tool restrictions, limit assistant capabilities to intended actions, and prevent assistants from accessing data outside the authenticated organisation context. |
| Third-Party Service Risk (Model Providers: OpenAI, Anthropic): Data handling, availability, or policy constraints of the Model Provider API impacting confidentiality, integrity, or availability. |
Third-Party Controls (OpenAI, Anthropic):
|
Potential Threats
- Unauthorised Access: Risk of unauthorised users gaining access to the platform or elevated privileges within an organisation (tenant) or across tenants.
- Organisation Isolation Failure: Risk of misconfiguration or application defects leading to cross-organisation data exposure.
- Data Breach / Data Exfiltration: Exposure of customer data due to weak access controls, credential compromise, or misconfigured storage/database/network rules.
- Credential and Secret Compromise: Exposure of sensitive credentials (for example, Model Provider API keys, database credentials, signing secrets) through insecure storage, logging, or operational access.
- Application Vulnerabilities: Exploitation of vulnerabilities in the web application, backend APIs, container images, or underlying VM OS.
- Supply Chain Risk: Malicious or vulnerable third-party dependencies or container base images impacting platform integrity.
- Denial of Service (DoS): Attacks that disrupt availability through request flooding, resource exhaustion, or abuse of AI endpoints.
- Prompt Injection / Data Leakage via AI: Attempts to manipulate assistant behaviour to disclose sensitive information, bypass controls, or retrieve data outside the user’s organisation context.
- Third-Party Service Risk (Model Providers: OpenAI, Anthropic): Data handling, availability, or policy constraints of the Model Provider API impacting confidentiality, integrity, or availability.
- Data Loss / Corruption (Accidental or Malicious): Risk of customer or platform data being deleted, corrupted, or rendered unrecoverable due to human error, software defects, malicious activity, or underlying infrastructure failure.
Mitigation Strategies
- Strong Authentication and Identity Controls: Use Microsoft Entra ID for SSO, with customers able to enforce MFA and Conditional Access. Apply least privilege via platform RBAC, including strict separation of AI Dojo super admin capabilities and organisation admin/user roles.
- Organisation Context Enforcement: Enforce organisation (tenant) scoping throughout application logic and data access. Validate organisation context on every request and for every database/storage operation to prevent cross-organisation access.
- Network Controls and Firewalls: Restrict access to PostgreSQL and Storage Accounts using firewall rules and IP allowlists limited to the platform infrastructure. Limit VM inbound traffic to required ports and paths using NSGs and controlled entry points.
- Encryption: Enforce TLS 1.2+ for all communications and encryption at rest (AES-256) for data stored in PostgreSQL and Storage Accounts.
- Secure Secrets Management: Store and access secrets using approved secure mechanisms, restrict operational access, rotate credentials where appropriate, and prevent secrets from being written to logs.
- Secure SDLC and Change Control: Use CI/CD pipelines with reviews and approvals, automated testing, and controlled promotion from non-production to production. Maintain auditable Infrastructure as Code for repeatable, consistent deployments.
- Hardening and Patch Management: Regularly patch VM operating systems and container base images. Apply vulnerability management processes for application dependencies and container images.
- Rate Limiting and Abuse Controls: Implement request throttling, resource limits, and guardrails to reduce the impact of DoS and excessive usage. Use caching (Redis) and capacity controls to protect shared resources.
- AI Safety and Data Leakage Controls: Apply defensive prompting and tool restrictions, limit assistant capabilities to intended actions, and prevent assistants from accessing data outside the authenticated organisation context.
- Third-Party Controls (OpenAI, Anthropic): Configure OpenAI usage with data sharing for training/improvement disabled and response storage disabled (for example,
store=false). Acknowledge that OpenAI may retain API content in abuse monitoring logs for up to 30 days by default, and monitor vendor policy changes as part of operational governance. Anthropic states that by default it does not use Anthropic API inputs/outputs to train models, and that Anthropic API inputs/outputs are deleted within 30 days subject to defined exceptions. - Backups and Recovery: Use managed database backup capabilities and Infrastructure as Code to support restoration and recovery following incidents or failures.
Monitoring, Detection, and Response
- Access Logging and Audit Trails: Record key application events and audit-relevant activity into dedicated PostgreSQL tables to support investigation and compliance needs.
- Operational Alerts: Implement alerts for resource saturation (for example, high CPU / low memory) and error rate anomalies to detect availability and performance issues early.
- Incident Response: AI Dojo maintains documented incident management processes covering triage, containment, eradication, recovery, and post-incident review, including customer communications where required.
4.6 Shared Responsibility Model
The AI Dojo Platform operates under a shared responsibility model, where security and compliance obligations are distributed between Microsoft Azure (as the cloud infrastructure provider), AI Dojo (as the SaaS platform operator), and the customer organisation.
| Responsibility Area | Microsoft Azure | AI Dojo | Customer |
|---|---|---|---|
| Physical data centre security | ✓ |
|
|
| Host infrastructure, hypervisor, and network fabric | ✓ |
|
|
| Azure platform service availability and resilience | ✓ |
|
|
| Platform-level encryption (at rest and in transit) | ✓ |
|
|
| Virtual machine and container patching |
|
✓ |
|
| Application-layer security and hardening |
|
✓ |
|
| Organisation (tenant) isolation and RBAC enforcement |
|
✓ |
|
| Secrets and credential management (Key Vault) |
|
✓ |
|
| Application logging, monitoring, and incident response |
|
✓ |
|
| Disaster recovery procedures and backup validation |
|
✓ |
|
| Identity provider governance (MFA, Conditional Access) |
|
|
✓ |
| User provisioning and access reviews |
|
|
✓ |
| Acceptable use and internal security policies |
|
|
✓ |
This model ensures that AI Dojo builds upon Microsoft Azure's certified and audited infrastructure controls, while maintaining responsibility for application-level security, multi-organisation isolation, and operational processes. Customers retain responsibility for identity governance within their own Microsoft Entra ID tenant and for ensuring appropriate use of the platform within their organisation.
5. Integration and Interoperability
5.1 Integration Points
The AI Dojo Platform integrates with a limited set of third-party services to provide AI inference, web-enabled assistants, transactional communications, billing, and customer support. These integrations are implemented server-side and are governed by least-privilege access controls and organisational context enforcement within the platform.
- Microsoft Entra ID (SSO): Used for user authentication via a multi-tenant Entra ID application registration. Customers can apply additional governance controls (for example, Conditional Access and MFA) in their Entra tenant, while day-to-day user access is primarily managed within the platform by organisation admins.
- Model Providers (AI Inference): OpenAI and Anthropic: Used to generate assistant responses and perform AI-powered processing. The platform sends user prompts and required context to the selected model provider for inference. Provider API keys are managed as secrets and are not exposed client-side.
- AI Dojo has opted out of sharing data for OpenAI model training or improvement, and response persistence is disabled for relevant endpoints (for example,
store=false). OpenAI may retain customer content in abuse monitoring logs for up to 30 days by default (unless legally required to retain longer). OpenAI API keys are managed as secrets and are not exposed client-side. - Anthropic states that by default it does not use Anthropic API inputs/outputs to train models, and that Anthropic API inputs/outputs are deleted within 30 days subject to defined exceptions.
- AI Dojo has opted out of sharing data for OpenAI model training or improvement, and response persistence is disabled for relevant endpoints (for example,
- Firecrawl (Web Search and Scraping): Used by web-capable assistants to perform searching and scraping of external websites. The platform sends search queries and/or URLs to retrieve, and Firecrawl returns retrieved web content. Firecrawl is accessed server-side only, and the scope of web access (broad web versus targeted domains) depends on the assistant configuration.
- Resend (Outbound Transactional Email): Used to send invitations, onboarding communications, and product tips. The platform sends recipient email addresses, template content, and delivery metadata required to deliver messages. The platform does not ingest inbound email.
- Stripe (Subscriptions and Billing): Used to manage subscription billing (plan and team-size based; no usage metering). The platform exchanges customer and subscription lifecycle data required for billing operations (for example, customer identifiers, plan selection, and billing status) using server-side integration patterns.
- Help Scout (Support and Help Documentation): Used to provide help documentation access and customer support workflows (including in-app support experiences and ticketing/escalation processes where enabled). Support requests and related metadata are processed within Help Scout according to configured support processes.
AI Dojo aims to minimise data shared with third-party services to what is required for functionality, and enforces organisation (tenant) context throughout the platform to reduce the risk of cross-organisation data exposure.
5.2 API and SDK
The AI Dojo Platform does not currently provide a public API or SDK for customer integration. All user interactions are performed through the web application. Any programmatic integration requirements are handled on a case-by-case basis and may be considered for future releases subject to product roadmap and security review.
5.3 Interoperability Standards
The AI Dojo Platform is designed to interoperate with customer environments using widely adopted web and identity standards:
- Web Standards: The platform is delivered as a browser-based application over HTTPS, using REST-style APIs between the front-end and backend services where applicable.
- Identity Standards: Authentication and single sign-on are implemented using Microsoft Entra ID via standard OAuth 2.0 and OpenID Connect (OIDC) flows, supporting enterprise identity governance controls such as MFA and Conditional Access.
- Data Formats: Platform communications and integrations use standard, structured formats (for example, JSON) to support consistent handling of requests, responses, and operational data.
6. Support and Maintenance
6.1 Support Plan & SLAs
The Support Plan for the AI Dojo Platform and associated Service Level Agreements (SLAs) are maintained in AI Dojo’s Help Scout documentation. Customers should refer to the Help Scout support documentation for the current support model, coverage, and SLA commitments.
6.2 Monitoring and Logging
Monitoring Mechanisms
-
Infrastructure Health Monitoring
The AI Dojo Platform uses Azure-native infrastructure monitoring to track the health and performance of the underlying compute and networking components (for example, VM availability and resource utilisation). Alerts are configured for key thresholds such as high CPU and low memory to enable proactive operational response.
-
Service Availability Monitoring
Basic service availability checks are used to detect outages or degraded access to the platform and trigger operational investigation where required.
Logging Mechanisms
-
Usage Analytics and Telemetry (Databricks Unity Catalog)
Platform usage analytics and telemetry data — including usage logs, assistant interaction metrics, and organisation-level analytics are stored in per-environment Unity Catalog tables within Azure Databricks. Access to telemetry data is controlled via Unity Catalog grants. This approach provides environment-level isolation of telemetry data, managed identity-based access control, and a scalable analytics layer backed by ADLS Gen2 storage.
-
Audit Logging
Security-relevant events (for example, administrative actions performed by AI Dojo super admins or organisation admins) are recorded in PostgreSQL audit tables to support investigation, governance, and compliance reporting.
Key Practices
- Centralised Log Storage: Application and audit logs are centrally stored in PostgreSQL to support querying, analysis, and operational investigation.
- Access Controls: Access to logs is restricted to authorised roles under least-privilege controls.
- Retention Policies: Log retention is configured to balance operational needs, compliance requirements, and storage management.
- Alerting and Response: Infrastructure alerts (such as CPU/memory thresholds) are configured to notify AI Dojo operations for timely triage and remediation.
6.3 Disaster Recovery Plan
Objective
The objective of this Disaster Recovery (DR) Plan is to ensure the AI Dojo Platform can recover from service disruptions while minimising downtime and data loss, and restoring secure service operation as quickly as practical.
Scope
This plan covers the AI Dojo Platform production environment hosted in Microsoft Azure Australia East, including application services (front-end and assistants containers), platform data stores (Azure Database for PostgreSQL, Azure Storage Accounts, Redis), and supporting infrastructure (networking and compute). It also considers dependencies on third-party services used by the platform (for example, OpenAI, Anthropic, Firecrawl, Stripe, Resend, and Help Scout).
Recovery Objectives
- Recovery Time Objective (RTO): Target ≤ 4 hours during business hours (Melbourne time: AEST/AEDT), depending on failure scope, complexity, and third-party dependencies. This target will be reviewed as the platform scales.
- Recovery Point Objective (RPO): ≤ 5 minutes (maximum acceptable data loss window, supported by Azure Database for PostgreSQL point-in-time restore capability).
Backup and Restore Strategy (Current)
- Azure Database for PostgreSQL: The platform relies on Azure Database for PostgreSQL managed backup capabilities, including daily snapshot backups and point-in-time restore within the configured retention window (7 days), with encryption at rest (AES‑256).
- Azure Storage Accounts: Uploaded files and branding assets are stored in Azure Storage and are protected via Azure storage redundancy (Locally-redundant storage - LRS) and encryption at rest (AES‑256).
- Configuration and Compute: Platform infrastructure and configuration are reproducible via Infrastructure as Code and container image redeployment.
High-Level Recovery Procedure
- Incident triage and containment: Assess impact, isolate the fault domain (application, database, storage, VM, or third-party dependency), and enact immediate containment steps.
- Service restoration:
- Redeploy platform containers from the approved images if the issue is application/compute related.
- Restore Azure Database for PostgreSQL using point-in-time restore to a new instance if required.
- Validate service health and data integrity post-restore (smoke tests, authentication checks, key user journeys).
- Operational verification: Confirm platform stability, monitor for recurrence, and validate key integrations.
- Communications: Provide customer updates through established support channels (Help Scout, Platform, Email), including status and expected timelines where appropriate.
- Post-incident review: Document root cause, corrective actions, and preventive measures.
Third-Party Dependency Considerations
Where third-party services are unavailable (for example, OpenAI or Firecrawl outages), the platform may operate in a degraded mode (for example, disabling web-capable assistants) or temporarily restrict functionality while maintaining core authentication and platform availability where possible.
Testing and Continuous Improvement (Roadmap / To Do)
AI Dojo maintains a DR improvement roadmap, including:
- Define and publish production RTO and RPO targets by customer tier.
- Establish a scheduled restore test cadence (for example, quarterly) and record outcomes.
- Formalise runbooks and escalation paths for common failure modes (database restore, VM rebuild, third-party outage).
- Evaluate additional resilience options (for example, multi-VM or zone-redundant architectures) as usage grows.
6.4 Software Updates and Patch Management
AI Dojo manages software updates and patching for the AI Dojo Platform as part of operating the SaaS service:
- Application Releases: Application changes are deployed via controlled CI/CD pipelines. Production releases are typically batched and aligned to sprint delivery, with a scheduled weekly release window (Monday mornings, Melbourne time — AEST/AEDT) to minimise disruption while the platform operates on a single-VM deployment. Where possible, releases are designed to incur minimal downtime (generally a brief service interruption while containers restart). As the platform evolves to support distributed deployments and rolling updates, AI Dojo may increase release cadence (including multiple releases per day) while maintaining change control and reliability.
- Infrastructure Updates: Infrastructure changes are managed via Infrastructure as Code and applied in a controlled manner to minimise disruption to customers. Where possible, changes are performed outside of business hours and validated through pre- and post-change checks.
- Security Patching:
- Virtual Machines: Platform Linux virtual machines run Ubuntu 22.04 LTS and are configured with Azure Update Manager for automatic security patching. Patch orchestration and assessment are set to
AutomaticByPlatform, enabling Azure-orchestrated scanning and patch installation. Critical and security patches are applied automatically within a defined weekly maintenance window (Sunday early morning AEST), with automatic reboot only when required (for example, kernel updates). Maintenance schedules are staggered across environments (dev before prod) to allow validation before production patching. This approach provides centralised visibility via the Azure portal and reduces operational overhead compared to manual patching. - Containers and Dependencies: Container base images and third-party dependencies are updated as part of the regular release cycle and accelerated when critical security issues are identified.
- Virtual Machines: Platform Linux virtual machines run Ubuntu 22.04 LTS and are configured with Azure Update Manager for automatic security patching. Patch orchestration and assessment are set to
- Change Control and Rollback: Production changes follow internal review, testing, and approval practices. Rollback procedures are maintained to restore the prior release if an update causes unexpected impact.
7. Performance and Optimisation
7.1 Performance Requirements
The AI Dojo Platform is designed to provide responsive, reliable assistant interactions for multi-tenant SaaS usage. Key performance requirements include:
- Interactive responsiveness: Typical user interactions should return responses within acceptable timeframes, noting that end-to-end latency depends on external AI inference times and network conditions.
- Availability and reliability: The platform should maintain high service availability and gracefully degrade where external dependencies are unavailable.
- Scalability: The platform should be able to scale to support increasing organisations, users, and concurrent conversations through controlled increases in compute and supporting services.
- Efficiency: Caching and data access patterns should minimise unnecessary load on PostgreSQL and external services.
- Operational stability: Resource usage (CPU, memory, disk, and network) should remain within safe operating thresholds under expected workloads.
7.2 Load Testing
Formal load testing is planned as part of the platform’s ongoing maturity. AI Dojo will use staged environments to validate performance under representative workloads, focusing on:
- Concurrent user activity and peak usage patterns.
- Assistant response latency distribution, including external model latency.
- Database and cache behaviour under sustained load (reads/writes, connection limits).
- Platform behaviour under failure scenarios (for example, degraded third-party dependencies).
Load testing outcomes and capacity thresholds will be reviewed periodically and used to inform scaling decisions and performance improvements.
7.3 Performance Tuning
AI Dojo applies a continuous performance optimisation approach, including:
- Caching strategy: Use Redis to cache frequently accessed configuration and reduce repeated database reads.
- Database optimisation: Apply indexing, query optimisation, and connection management to ensure stable performance as data volume grows.
- Compute scaling: Scale VM resources (and service allocations) based on observed usage patterns, with controlled changes via Infrastructure as Code.
- External dependency management: Apply sensible timeouts, retries, and backoff for third-party services (for example, OpenAI and Firecrawl) and communicate degraded modes where applicable.
- Payload optimisation: Reduce unnecessary request/response size and avoid redundant upstream calls where possible.
- Release discipline: Validate performance impacts in non-production environments prior to production release, and monitor post-release behaviour to detect regressions.
8. Appendices
8.1 Glossary
| Term/Acronym | Definition |
|---|---|
| ACR | Azure Container Registry — managed Docker container registry service in Microsoft Azure. |
| ADLS Gen2 | Azure Data Lake Storage Gen2 — Azure Blob Storage with Hierarchical Namespace (HNS) enabled, providing file system semantics, directory-level security, and optimised analytics performance. |
| AI | Artificial Intelligence — simulation of human intelligence processes by machines, especially computer systems. |
| API | Application Programming Interface — a set of rules that allows software components to communicate. |
| APM | Application Performance Monitoring — processes and tools used to monitor and manage application performance and availability. |
| Assistant | In the context of the AI Dojo Platform, an assistant is an AI-powered capability that interacts with users via natural language and is configured for a specific workflow (primarily accounting-focused). |
| Azure | Microsoft Azure — cloud computing platform providing compute, networking, storage, and managed services. |
| CI/CD | Continuous Integration / Continuous Delivery — automated build, test, and deployment processes used to release software changes. |
| DRP | Disaster Recovery Plan — documented procedures to recover and protect IT services in the event of a disruption. |
| Entra ID | Microsoft Entra ID (formerly Azure Active Directory / Azure AD) — cloud identity and access management service used for authentication and SSO. |
| HA | High Availability — design approach that improves service uptime and resilience. |
| ITSM | IT Service Management — activities and processes for planning, delivering, operating, and controlling IT services. |
| JSON | JavaScript Object Notation — lightweight data interchange format. |
| Organisation (Tenant) | A customer entity within the AI Dojo Platform. The platform is multi-organisation and logically isolates data and configuration per organisation. |
| RBAC | Role-Based Access Control — access control model where permissions are granted based on roles. |
| RPO | Recovery Point Objective — maximum tolerable period in which data might be lost due to an incident. |
| RTO | Recovery Time Objective — maximum acceptable time to restore a service after an incident. |
| SaaS | Software as a Service — software delivered and operated by the provider and accessed by customers over the internet. |
| SLA | Service Level Agreement — formal agreement defining service levels and support commitments. |
| Unity Catalog | A centralised data governance solution for Azure Databricks that provides unified access control, auditing, lineage, and data discovery across workspaces and cloud storage. |
| VM | Virtual Machine — software emulation of a physical computer that runs an operating system and applications. |
| VNet | Virtual Network — logically isolated network within Azure providing connectivity between resources. |
| VPN | Virtual Private Network — extends a private network across a public network. |
| YAML | YAML Ain’t Markup Language — human-readable data serialisation format often used for configuration files. |
8.2 References
- Microsoft. “Azure Architecture Center.” Microsoft Learn. Retrieved from: https://learn.microsoft.com/en-us/azure/architecture/
- Microsoft. “Virtual machines in Azure.” Microsoft Learn. Retrieved from: https://learn.microsoft.com/en-us/azure/virtual-machines/overview
- Microsoft. “What is Azure Virtual Network?” Microsoft Learn. Retrieved from: https://learn.microsoft.com/en-us/azure/virtual-network/virtual-networks-overview
- Microsoft. “What is Azure Front Door?” Microsoft Learn. Retrieved from: https://learn.microsoft.com/en-us/azure/frontdoor/front-door-overview
- Microsoft. “Azure Storage encryption for data at rest.” Microsoft Learn. Retrieved from: https://learn.microsoft.com/en-us/azure/storage/common/storage-service-encryption
- Microsoft. “Backup and restore in Azure Database for PostgreSQL.” Microsoft Learn. Retrieved from: https://learn.microsoft.com/en-us/azure/postgresql/flexible-server/concepts-backup-restore
- Microsoft. “Microsoft Entra ID documentation.” Microsoft Learn. Retrieved from: https://learn.microsoft.com/en-us/entra/identity/
- OpenAI. “API Reference – Introduction.” OpenAI Platform Docs. Retrieved from: https://platform.openai.com/docs/api-reference/introduction
- OpenAI. “Data controls in the OpenAI platform.” OpenAI Platform Docs. Retrieved from: https://platform.openai.com/docs/guides/your-data
- Microsoft. “Designing for efficiency and scalability on Azure (paired regions / availability guidance).” Microsoft Learn. Retrieved from: https://learn.microsoft.com/en-us/azure/best-practices-availability-paired-regions
- Anthropic. “Is my data used for model training? (Commercial Customers).” Anthropic Privacy Center. https://privacy.claude.com/en/articles/7996868-is-my-data-used-for-model-training
- Anthropic. “How long do you store my organization’s data? (Commercial Customers).” Anthropic Privacy Center. https://privacy.claude.com/en/articles/7996866-how-long-do-you-store-my-organization-s-data
- Microsoft. "Azure Trust Center." Retrieved from: https://azure.microsoft.com/en-au/explore/trusted-cloud/
- Microsoft. "Azure Compliance Offerings." Microsoft Learn. Retrieved from: https://learn.microsoft.com/en-us/azure/compliance/offerings/
- Microsoft. "Microsoft Purview Compliance Manager." Microsoft Learn. Retrieved from: https://learn.microsoft.com/en-us/purview/compliance-manager
- Microsoft. "Shared responsibility in the cloud." Microsoft Learn. Retrieved from: https://learn.microsoft.com/en-us/azure/security/fundamentals/shared-responsibility
- Microsoft. "What is Azure Databricks?" Microsoft Learn. Retrieved from: https://learn.microsoft.com/en-us/azure/databricks/introduction/
- Microsoft. "Unity Catalog overview." Microsoft Learn. Retrieved from: https://learn.microsoft.com/en-us/azure/databricks/data-governance/unity-catalog/
- Microsoft. "Azure Data Lake Storage Gen2 introduction." Microsoft Learn. Retrieved from: https://learn.microsoft.com/en-us/azure/storage/blobs/data-lake-storage-introduction
- Microsoft. "Azure Container Registry documentation." Microsoft Learn. Retrieved from: https://learn.microsoft.com/en-us/azure/container-registry/
8.3 Contact Information
Solution Architect
Alistair Toms
E: Alistair.Toms@ai-dojo.com.au
M: 0421 190 338
Data Engineer
Yi Xiang Chee
E: Yixiang.Chee@ai-dojo.com.au
M: 0478 913 462
Software Engineer
Vincent Taneli
E: Vincent.Taneli@ai-dojo.com.au
M: 0406 221 916